











Sketching the Future: Applying Conditional Control Techniques to Text-to-Video Models
- Rohan Dhesikan
- Vignesh Rajmohan
Abstract
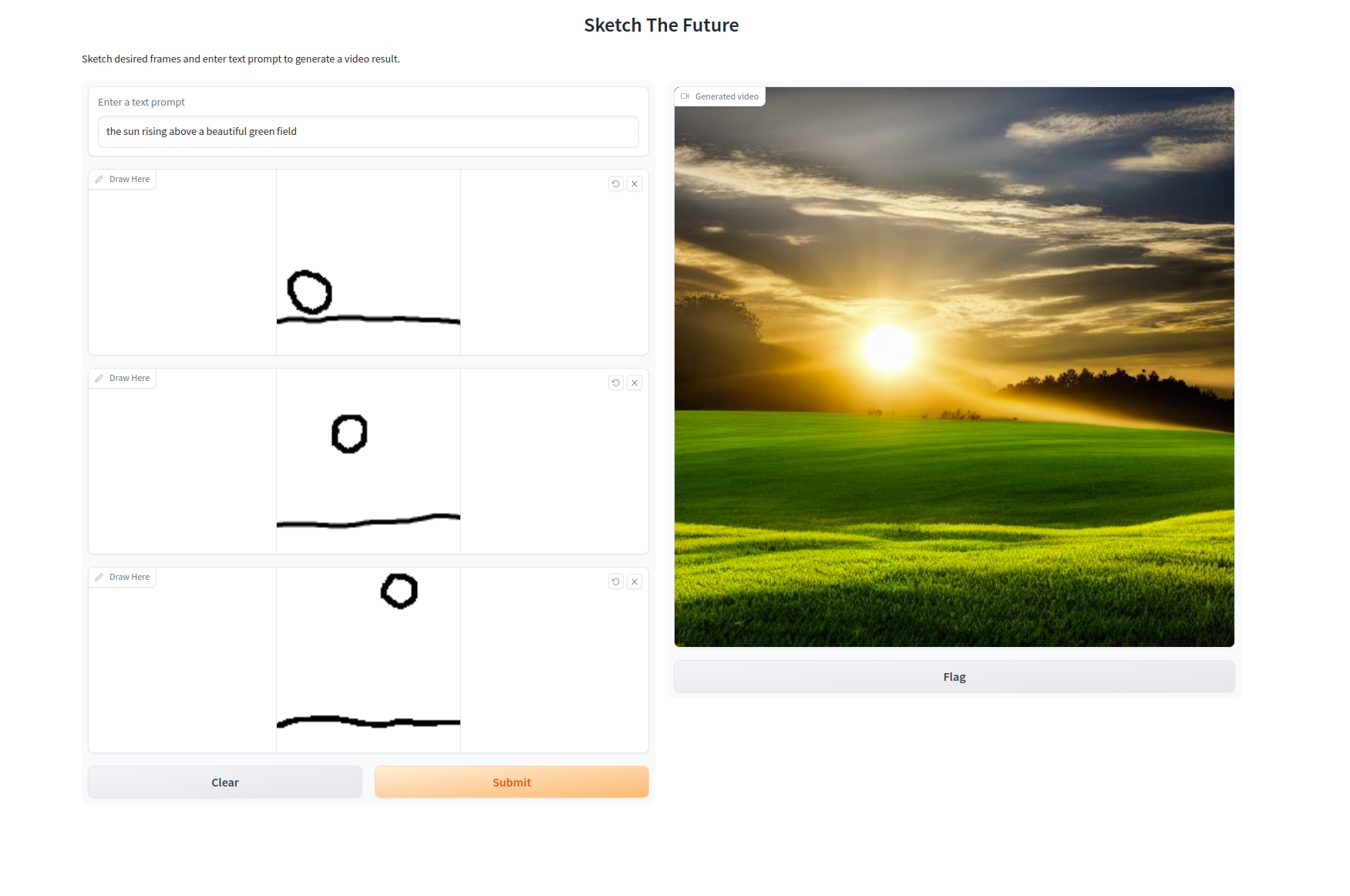
The proliferation of video content demands efficient and flexible neural network- based approaches for generating new video content. In this paper, we propose a novel approach that combines zero-shot text-to-video generation with ControlNet to improve the output of these models. Our method takes multiple sketched frames as input and generates video output that matches the flow of these frames, building upon the Text-to-Video Zero architecture and incorporating ControlNet to enable additional input conditions. By first interpolating frames between the inputted sketches and then running Text-to-Video Zero using the new interpolated frames video as the control technique, we leverage the benefits of both zero-shot text- to-video generation and the robust control provided by ControlNet. Experiments demonstrate that our method excels at producing high-quality and remarkably consistent video content that more accurately aligns with the user’s intended motion for the subject within the video.
Video
Try it out!
Acknowledgements
The authors would like to thank Professor Pathak and the course staff of Visual Learning and Recognition for their support and Mrinal Verghese for his compute resources.
The website template was borrowed from Jon Barron.